Article
Kiến trúc SOC AI AGENT
ĐỀ XUẤT KIẾN TRÚC SOC AI AGENT
ĐỀ XUẤT KIẾN TRÚC SOC AI AGENT
Common Ticket Hub + Tier 1/Tier 3 Feedback Learning
Phiên bản: 1.0 | Ngày: 09/06/2026
Mục tiêu tài liệu Thiết kế kiến trúc SOC AI Agent dựa trên pattern của các sản phẩm SOC AI trả phí, nhưng tối ưu cho mô hình doanh nghiệp có một nguồn dữ liệu chung là ticket/case, có phân tích Tier 1, kết luận Tier 3 và vòng học hỏi được kiểm soát để cải thiện độ chính xác. |
Mục lục
1. Tóm tắt điều hành
2. Bối cảnh từ các sản phẩm SOC AI trả phí
3. Nguyên tắc kiến trúc mục tiêu
4. Kiến trúc tổng thể
5. Common Ticket / Case Data Hub
6. SOC AI Agent Layer
7. Vòng học hỏi từ Tier 1 và Tier 3
8. Cơ chế cải thiện độ chính xác
9. Workflow vận hành end-to-end
10. Data model đề xuất
11. Governance, bảo mật và human-in-the-loop
12. Mapping với sản phẩm trả phí
13. Roadmap MVP 8-12 tuần
14. KPI và mô hình đo hiệu quả
15. Rủi ro và biện pháp kiểm soát
16. Khuyến nghị triển khai
17. Phụ lục: nguồn tham khảo
1. Tóm tắt điều hành
SOC AI Agent nên được triển khai như một lớp điều phối thông minh phía trên SIEM/XDR/SOAR hiện có. Trọng tâm không phải là chatbot hỏi đáp log, mà là một hệ thống agent có khả năng triage, điều tra, tìm case tương tự, tạo giả thuyết, tổng hợp evidence, đề xuất hành động và học từ kết luận đã được analyst xác nhận.
Kết luận chính Nguồn dữ liệu học quan trọng nhất là Common Ticket / Case Hub. AI chỉ được học từ ticket đã đóng, có final verdict của Tier 3, đủ evidence, có root cause/reasoning và được đánh dấu approved_for_learning. |
Khía cạnh | Đề xuất |
Mục tiêu | Giảm thời gian triage, tăng consistency, giảm false positive lặp lại, tăng chất lượng điều tra và detection engineering. |
Nguồn dữ liệu học | Ticket/case đã xử lý, gồm nhận định Tier 1, phân tích Tier 3, evidence, final verdict, action và feedback. |
Cách học an toàn | Ưu tiên case memory, RAG, feedback scoring, rule tuning và confidence calibration trước khi fine-tune. |
Vai trò con người | Tier 1 dùng AI để triage nhanh; Tier 3 là nguồn ground truth; SOC Lead duyệt thay đổi rule/playbook có rủi ro. |
Triển khai khuyến nghị | Hybrid: tận dụng AI native của vendor nhưng giữ Common Ticket Hub và Learning Layer nội bộ để tránh lock-in. |
2. Bối cảnh từ các sản phẩm SOC AI trả phí
Các sản phẩm thương mại hiện đại đang đi theo hướng agentic SOC: assistant không chỉ trả lời câu hỏi, mà còn có khả năng phối hợp nhiều bước triage, investigation, automation và response trong phạm vi được kiểm soát. Các pattern cần học hỏi gồm:
Sản phẩm | Pattern có thể học cho kiến trúc nội bộ |
Microsoft Security Copilot | Security agent tích hợp Defender/Entra/Intune/Purview; phù hợp pattern grounding theo dữ liệu tổ chức, promptbook, agent workflow và human approval. |
Google Security Operations / Gemini Agentic SOC | Tập trung vào triage, investigation, hunting và detection engineering; phù hợp pattern agent đọc alert, enrich, generate query và respond có kiểm soát. |
CrowdStrike Charlotte AI / Agentic SOAR | Kết hợp AI reasoning với SOAR workflow; phù hợp pattern orchestrated investigation và user-authorized action. |
Palo Alto Cortex XSIAM / Agentix | Hợp nhất SIEM/XDR/SOAR và agentic experience; phù hợp pattern central data, correlation, automation và response. |
Splunk AI Assistant in Security | Hỗ trợ detection, triage, investigation, response, automation, SPL/report generation và workflow recommendation. |
SentinelOne Purple AI | Human-in-the-loop, data privacy safeguards, agentic triage/investigation/response và mở rộng sang third-party SIEM/data lake. |
Bài học thiết kế Paid products thường mạnh trong ecosystem của chính vendor. Vì vậy, kiến trúc doanh nghiệp nên có Common Ticket Hub và Enterprise SOC AI Orchestrator để gom tri thức vận hành, giữ dữ liệu học riêng và giảm phụ thuộc vendor. |
3. Nguyên tắc kiến trúc mục tiêu
Nguyên tắc | Diễn giải |
Evidence-first | Mọi nhận định của AI phải trích được evidence: log, alert, process tree, email header, IOC enrichment, asset context hoặc ticket trước đó. |
Tier 3 as ground truth | Final verdict của Tier 3 có trọng số cao nhất. Nhận định Tier 1 là tín hiệu tham khảo, không phải dữ liệu học cuối cùng. |
Human-in-the-loop | Hành động read-only có thể tự động; hành động write/risk cao cần Tier 2/Tier 3/SOC Lead phê duyệt. |
Version everything | Lưu model_version, prompt_version, runbook_version, rule_version và tool_call để debug khi AI sai. |
Learning by approval | Chỉ đưa case vào learning queue khi đủ điều kiện chất lượng và được approved_for_learning. |
Start with retrieval, not fine-tuning | Giai đoạn đầu dùng RAG/case memory/calibration. Fine-tuning chỉ làm khi dữ liệu sạch và có eval dataset đủ mạnh. |
Fail closed | Khi AI thiếu bằng chứng hoặc tool lỗi, hệ thống phải trả về trạng thái cần analyst review, không tự kết luận benign/malicious. |
4. Kiến trúc tổng thể
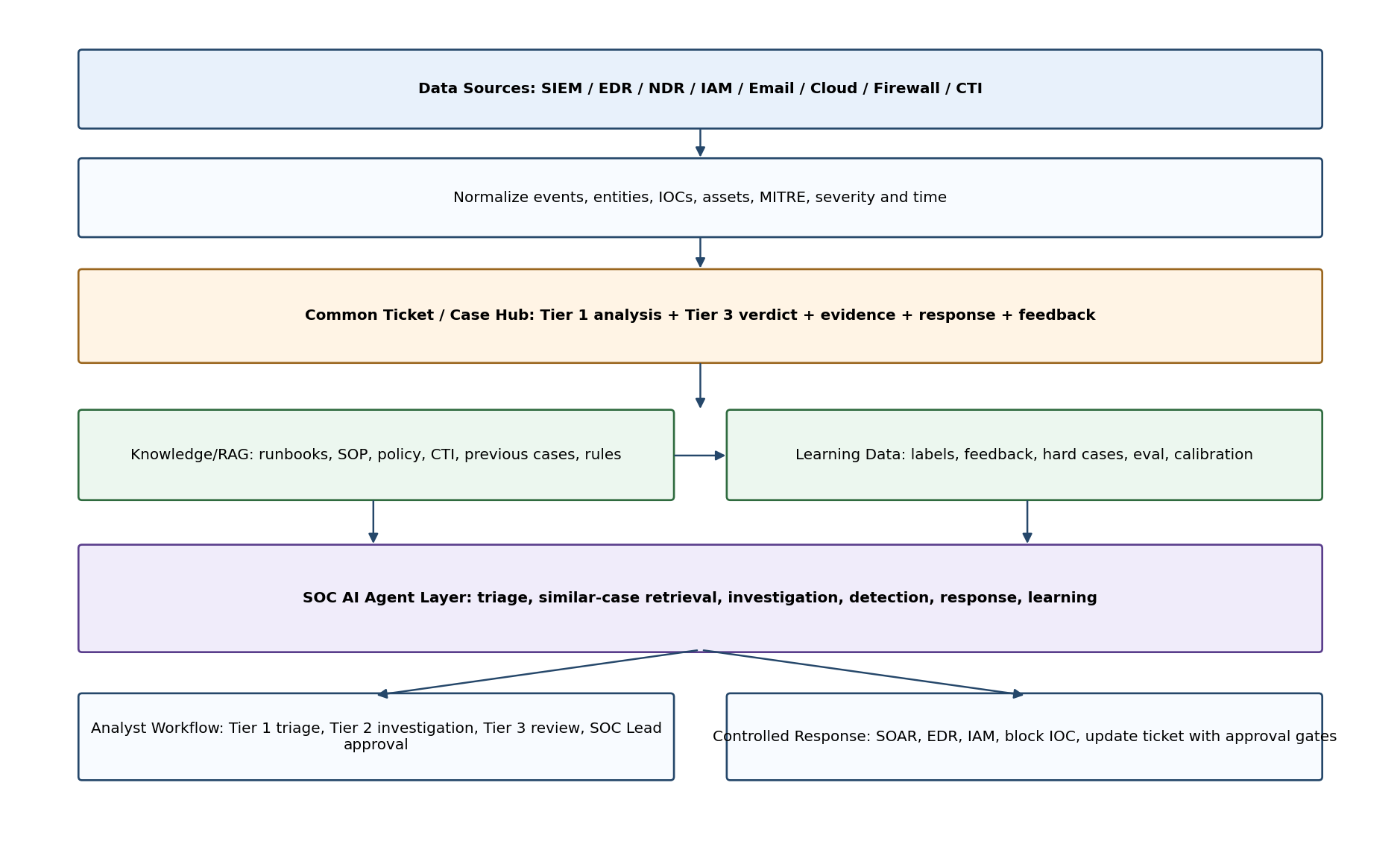
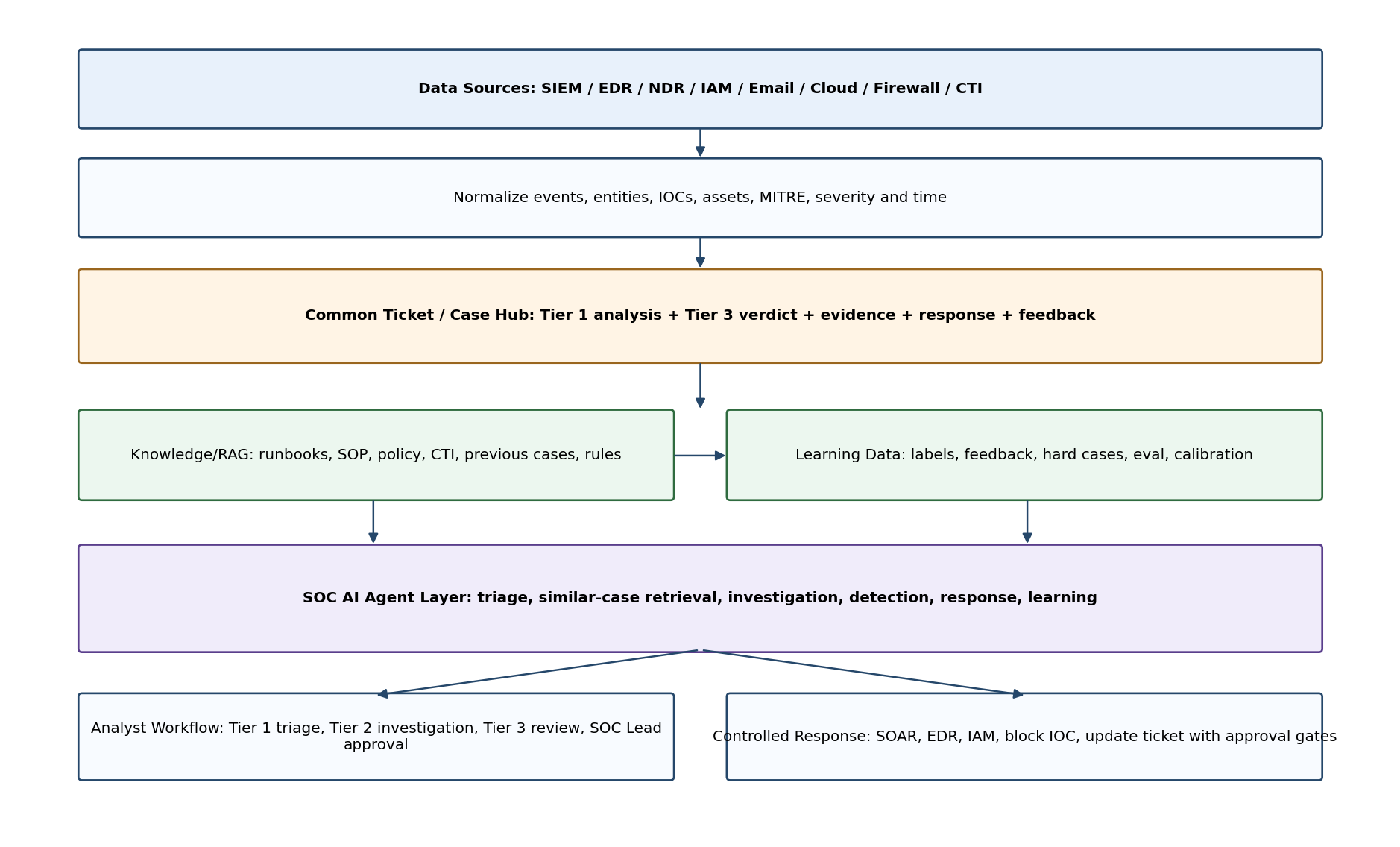
Hình 1. Kiến trúc tổng thể SOC AI Agent với Common Ticket Hub làm trung tâm.
Layer | Thành phần | Vai trò |
Security Data Sources | SIEM, EDR/XDR, NDR, IAM, Email Security, Cloud, Firewall, Proxy, CTI | Cung cấp alert, raw log, context, IOC và telemetry phục vụ điều tra. |
Normalization & Evidence | Parser, entity resolver, MITRE mapper, IOC enrichment, asset/user profile | Chuẩn hóa dữ liệu để agent có thể so sánh case và sinh evidence nhất quán. |
Common Ticket Hub | ServiceNow/Jira/TheHive/Sentinel/Splunk ES/XSOAR incidents | Nguồn dữ liệu chung cho analyst notes, verdict, evidence, response action và feedback. |
Knowledge / RAG | Runbook, SOP, policy, previous cases, CTI, detection rules, postmortem | Grounding cho AI, giảm hallucination và tăng tính nhất quán. |
Learning Data Layer | Labels, feedback, hard cases, eval set, calibration, performance metrics | Tạo vòng học hỏi có kiểm soát để cải thiện accuracy. |
SOC AI Agent Layer | Triage, Similar Case, Investigation, Detection, Response, Learning agents | Điều phối phân tích, đề xuất, tự động hóa và cập nhật tri thức. |
Analyst Workflow | Tier 1, Tier 2, Tier 3, SOC Lead | Phê duyệt, sửa sai, gắn nhãn và xác nhận kết luận. |
Controlled Response | SOAR, EDR isolate, IAM disable, block IOC, update ticket | Thực thi action theo risk gate và audit trail. |
5. Common Ticket / Case Data Hub
Common Ticket Hub là nguồn dữ liệu học chung, đồng thời là hệ thống điều phối workflow giữa Tier 1, Tier 2/Tier 3, SOC Lead và AI. Hệ thống này cần chuẩn hóa schema để mọi case đều có cùng ngôn ngữ dữ liệu.
Nhóm trường | Trường cần có | Mục đích |
Case metadata | case_id, alert_id, source_product, created_at, closed_at, owner, status | Truy vết vòng đời case và đo SLA. |
Alert context | alert_name, severity_initial, severity_final, MITRE tactic/technique | Đánh giá chất lượng detection và severity scoring. |
Entities | user, host, IP, domain, process, file hash, cloud account, mailbox | Tạo graph điều tra và tìm case tương tự. |
Tier 1 analysis | initial_verdict, summary, confidence, questions, escalation_reason | Lưu nhận định ban đầu và điểm cần kiểm chứng. |
Tier 3 analysis | final_verdict, root_cause, confidence, missing_checks, recommended_tuning | Ground truth cho vòng học hỏi. |
Evidence | log references, query results, process tree, IOC enrichment, screenshots, attachments | Bảo đảm AI và analyst có căn cứ. |
Response | containment, eradication, recovery, notification, rule tuning | Ghi lại hành động xử lý và hiệu quả. |
Learning flags | approved_for_learning, quality_score, reopen_status, hard_case_tag | Kiểm soát dữ liệu nào được đưa vào học. |
{ "case_id": "SOC-2026-000123", "alert_name": "Suspicious PowerShell Encoded Command", "source": "EDR", "severity_initial": "High", "severity_final": "Medium", "entities": { "user": "user01", "host": "PC-001", "process": "powershell.exe", "parent_process": "sccmclient.exe", "hash": "..." }, "tier1_analysis": { "initial_verdict": "Suspicious", "confidence": 65, "summary": "PowerShell encoded command observed on endpoint." }, "tier3_analysis": { "final_verdict": "Benign positive", "confidence": 95, "root_cause": "Approved SCCM deployment script", "recommended_tuning": "Suppress when parent=sccmclient.exe and signed script hash is approved" }, "learning_status": "approved_for_learning"}6. SOC AI Agent Layer
Agent | Input | Output chính | Người kiểm soát |
Triage Agent | Alert, entity context, previous cases, runbook, CTI | Verdict sơ bộ, severity, confidence, recommended next steps | Tier 1 |
Similar Case Retrieval Agent | Feature của case mới và vector index case đã đóng | Danh sách case tương tự, điểm giống/khác, verdict lịch sử | Tier 1/Tier 3 |
Investigation Agent | Hypothesis, SIEM/EDR tools, raw logs, asset/user context | Timeline, evidence, supporting/refuting facts, scope | Tier 2/Tier 3 |
Tier 3 Reviewer Agent | Tier 1 analysis, AI triage, evidence | Missing checks, chất lượng phân tích, đề xuất verdict/rule tuning | Tier 3 |
Detection Engineering Agent | Closed cases, FP clusters, missed detections, MITRE gaps | Sigma/KQL/SPL/YARA-L draft, test plan, tuning recommendation | Tier 3/SOC Lead |
Response Recommendation Agent | Verdict, asset criticality, business impact, runbook | Containment/remediation plan, risk rating, approval requirement | Tier 2/Tier 3/SOC Lead |
Feedback & Learning Agent | AI prediction, Tier 1 feedback, Tier 3 verdict, reopen status | Learning queue, hard-case dataset, calibration update, memory update | SOC Lead/Tier 3 |
7. Vòng học hỏi từ Tier 1 và Tier 3
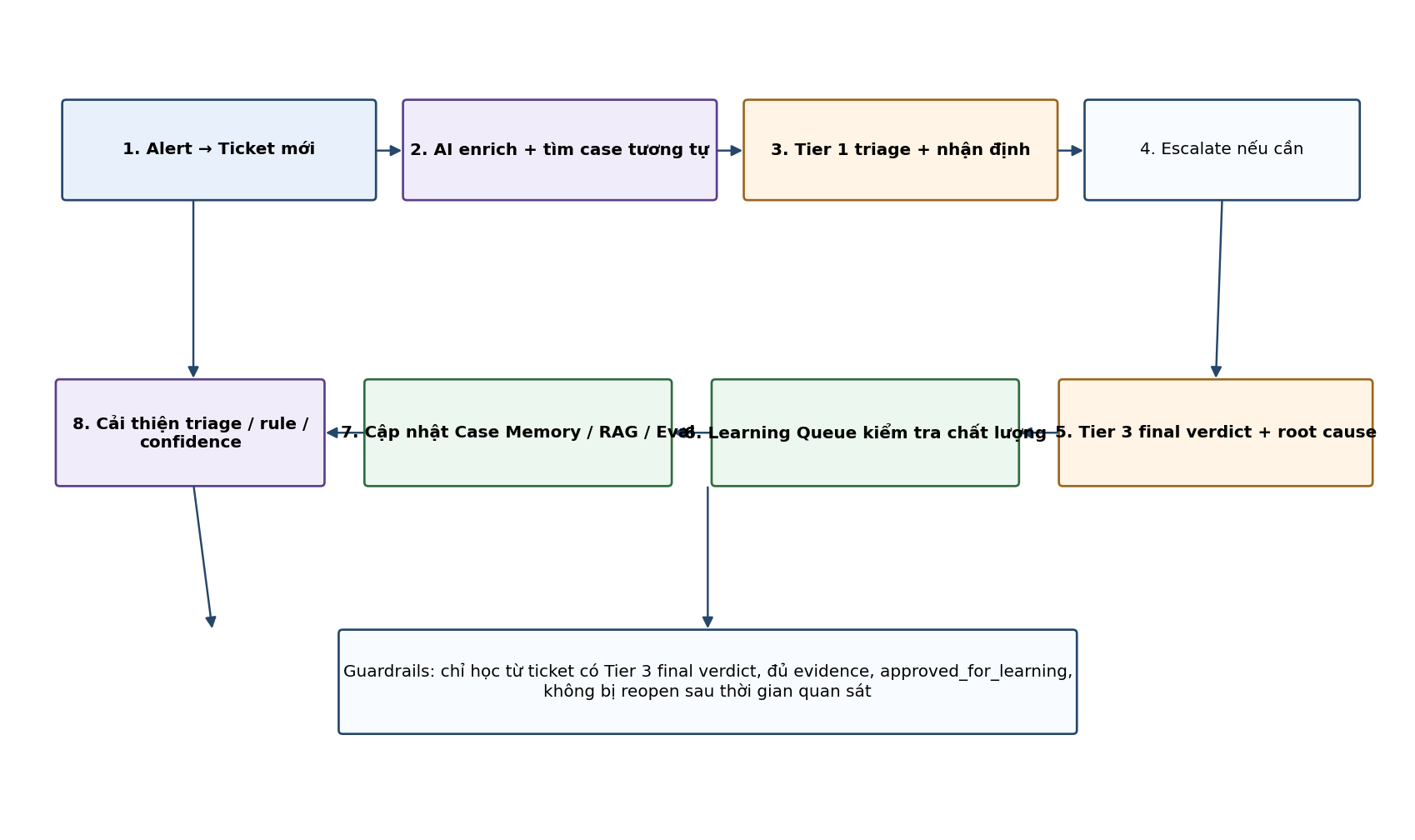
Hình 2. Vòng học hỏi có kiểm soát từ ticket đã đóng.
Nguồn feedback | Trọng số đề xuất | Cách sử dụng |
Tier 1 initial verdict | 0.3 | Dùng để đánh giá hỗ trợ triage và phát hiện thiếu sót trong checklist. Không dùng làm ground truth cuối. |
Tier 2 verification | 0.6 | Dùng để cải thiện investigation path và bổ sung evidence. |
Tier 3 final verdict | 1.0 | Ground truth chính để cập nhật case memory, eval dataset và calibration. |
SOC Lead approval | 1.0 | Bắt buộc với rule tuning, playbook update hoặc action policy. |
Auto-close không review | 0.1 | Chỉ dùng làm tín hiệu yếu; tránh đưa vào training mạnh. |
Case bị reopen | Negative feedback | Đưa vào hard-case dataset, giảm confidence pattern tương ứng. |
Điểm kiểm soát quan trọng Nếu Tier 1 kết luận false positive nhưng Tier 3 xác nhận true positive, AI không được học theo Tier 1. Case này phải được đánh dấu hard_case để lần sau agent giảm confidence cho hướng benign và yêu cầu thêm điều tra. |
8. Cơ chế cải thiện độ chính xác
Cơ chế | Mô tả | Ưu tiên |
Similar-case learning | Vector hóa case đã đóng, tìm pattern tương tự, so sánh điểm giống/khác trước khi đưa verdict. | P0 |
Feedback scoring | Lưu dự đoán AI, confidence, verdict của Tier 1/Tier 3, đúng/sai, error_type và root cause của sai lệch. | P0 |
Rule tuning loop | Gom cụm false positive/missed detection, sinh tuning candidate, Tier 3/SOC Lead approve, test trước khi promote. | P1 |
Hard-case dataset | Tập hợp case AI sai, case bị reopen, case Tier 1/Tier 3 mâu thuẫn để regression test. | P1 |
Confidence calibration | So sánh confidence AI với accuracy thực tế để hiệu chỉnh điểm tin cậy. | P1 |
Fine-tuning | Chỉ xem xét sau khi dữ liệu sạch, có nhãn chuẩn, eval ổn định và governance rõ. | P2 |
Closed ticket -> Quality check -> Learning queue -> Update case memory / RAG / eval set -> Run regression evaluation -> SOC Lead approval -> Production updateQuality gates: - Có Tier 3 final verdict - Có evidence rõ ràng - Có root cause hoặc reasoning - Không bị reopen trong thời gian quan sát - Có approved_for_learning = true9. Workflow vận hành end-to-end
9.1. Alert triage workflow
1. Alert sinh ra từ SIEM/XDR/EDR và tự động tạo ticket.
2. AI enrich IOC, user, host, asset criticality, alert history và MITRE mapping.
3. Similar Case Agent tìm các ticket đã đóng có pattern tương tự.
4. Triage Agent đưa verdict sơ bộ, confidence, severity và checklist điều tra.
5. Tier 1 xác nhận, sửa hoặc escalate lên Tier 2/Tier 3.
6. Tier 3 đưa final verdict, root cause và đề xuất tuning nếu cần.
7. Learning Agent chỉ nhận dữ liệu sau khi case đạt quality gate.
9.2. Rule tuning workflow
1. AI phát hiện cụm false positive lặp lại từ closed tickets.
2. Detection Engineering Agent sinh tuning candidate hoặc rule draft.
3. Tier 3 kiểm tra logic, false negative risk và business impact.
4. Rule được deploy ở test/silent mode trong 7-14 ngày.
5. Nếu không tăng missed detection, SOC Lead approve promote production.
6. Kết quả được lưu vào rule_version và case memory.
9.3. Response workflow
1. AI đề xuất containment/remediation dựa trên runbook và asset criticality.
2. Low-risk action có thể tự động update ticket hoặc gắn tag.
3. Medium-risk action cần Tier 2 approve.
4. High-risk action như isolate host, disable account, block production firewall cần Tier 3/SOC Lead approve.
5. Mọi action phải có audit log, actor, timestamp, reason và rollback plan.
10. Data model đề xuất
Bảng | Trường chính | Vai trò |
soc_cases | case_id, alert_id, source_product, created_at, closed_at, status, final_verdict, root_cause | Bảng trung tâm quản lý vòng đời case. |
case_entities | case_id, entity_type, entity_value, role, first_seen, last_seen | Lưu user/host/IP/domain/process/hash để correlation và retrieval. |
case_evidence | evidence_id, case_id, evidence_type, reference_uri, query, collected_at, integrity_hash | Lưu bằng chứng và liên kết đến nguồn gốc. |
analyst_feedback | feedback_id, case_id, analyst_tier, verdict, comment, correction_type, confidence | Lưu phản hồi Tier 1/Tier 3 và dữ liệu sửa sai. |
ai_predictions | prediction_id, case_id, agent_name, prediction, confidence, evidence_used, model_version, prompt_version, correct_after_review | Đo accuracy và debug lỗi AI. |
case_embeddings | case_id, embedding_text, vector, final_verdict, tags, quality_score | Tìm case tương tự và case memory. |
learning_queue | item_id, case_id, learning_type, proposed_change, risk_level, approval_status | Điều phối cập nhật KB/rule/prompt/calibration. |
eval_runs | eval_id, dataset_version, model_version, prompt_version, precision, recall, false_negative_count | Theo dõi chất lượng trước/sau thay đổi. |
11. Governance, bảo mật và human-in-the-loop
Loại hành động | AI được tự làm? | Ví dụ | Kiểm soát |
Read-only | Có | Query SIEM, enrich IOC, tìm case tương tự, đọc runbook | RBAC, query audit, rate limit. |
Low-risk write | Có thể | Update ticket summary, gắn tag, tạo checklist | Lưu diff, analyst có thể revert. |
Medium-risk | Cần approve | Tạo blocklist draft, tạo rule draft, mở hunting job rộng | Tier 2/Tier 3 approval. |
High-risk | Cần approve mạnh | Isolate host, disable user, block domain/IP production | Tier 3/SOC Lead approval, change record, rollback. |
Destructive / mass action | Không tự động | Delete/quarantine diện rộng, kill process hàng loạt | Manual change process. |
Rủi ro AI | Biện pháp kiểm soát |
Hallucination | Evidence-first output, citation bắt buộc, fail closed khi thiếu dữ liệu. |
Prompt injection từ email/log/web | Tách untrusted content, sanitize input, policy checker trước tool call. |
Data leakage | Redaction PII/secrets, tenant isolation, private model option, DLP. |
Tool over-permission | Least privilege per agent, scoped credentials, action allowlist. |
Model drift | Monthly eval, hard-case regression, monitor precision/recall và reopen rate. |
Vendor lock-in | Giữ schema ticket, case memory, eval dataset và playbook ở lớp nội bộ. |
12. Mapping với sản phẩm trả phí
Capability | Paid product pattern | Thiết kế in-house tương ứng |
Security copilot/assistant | Security Copilot, Gemini SecOps, Charlotte AI, Cortex AI/Agentix, Splunk AI Assistant, Purple AI | SOC AI Agent UI + Agent Orchestrator. |
Central data | Sentinel/Defender, Google SecOps, Falcon, XSIAM, Splunk ES, Singularity Data Lake | Security Data Lake + normalization layer. |
Case management | Sentinel incident, SecOps case, Falcon incident, XSIAM/XSOAR, Splunk ES notable/case, Singularity case | Common Ticket / Case Hub. |
Agent workflow | Promptbook/agent, agentic SOC, agentic SOAR, automation workflow | Planner/executor + tool registry + approval gate. |
Feedback learning | Analyst feedback, workflow validation, human approval, model/prompt iteration | Feedback & Learning Agent + learning queue + eval harness. |
Detection engineering | Detection/rule assistant, YARA-L/SPL/KQL generation, tuning recommendations | Detection Engineering Agent + rule test/promotion workflow. |
Human control | Human-in-the-loop, user-authorized action, guided response | Risk taxonomy + approval policy + audit log. |
13. Roadmap MVP 8-12 tuần
Phase | Thời lượng | Mục tiêu | Deliverables |
Phase 0 - Assessment | 1-2 tuần | Đánh giá SOC process, alert volume, data sources, ticket quality và use-case ưu tiên. | Readiness report, source inventory, use-case backlog, KPI baseline. |
Phase 1 - Common Ticket Schema | 2 tuần | Chuẩn hóa fields và workflow Ticket Hub. | Schema, taxonomy TP/FP/BP, approved_for_learning, dashboard chất lượng ticket. |
Phase 2 - AI Triage + Similar Case | 3-4 tuần | Agent đọc ticket mới, tìm case tương tự, đưa verdict/checklist. | Triage Agent, case embedding index, analyst UI, audit log. |
Phase 3 - Feedback Loop | 2 tuần | So sánh AI prediction với Tier 3 verdict, ghi error_type và cập nhật learning queue. | ai_predictions table, feedback scoring, hard-case dataset, eval report. |
Phase 4 - Detection Tuning Pilot | 2-3 tuần | Gom false positive cluster, sinh rule tuning draft, test và approval. | Rule tuning candidate, test/silent mode, approval workflow, KPI reduction report. |
14. KPI và mô hình đo hiệu quả
KPI | Định nghĩa | Mục tiêu 3 tháng đầu |
Ticket có final verdict | Tỷ lệ ticket đóng có verdict chuẩn hóa của Tier 3/Tier 2 được ủy quyền. | > 90% |
Approved for learning | Tỷ lệ closed cases đủ chất lượng và được phép dùng làm dữ liệu học. | > 60% |
AI triage precision | AI đánh suspicious/malicious thì sau review đúng bao nhiêu. | > 75% |
False negative count | Số case AI đánh benign nhưng Tier 3 xác nhận malicious. | 0 hoặc giảm mạnh theo tháng |
Analyst override rate | Tỷ lệ analyst phải sửa verdict/severity/checklist của AI. | Giảm dần theo tháng |
MTTA reduction | Giảm thời gian nhận biết/triage ban đầu. | 30-50% |
False positive reduction | Giảm alert/ticket benign lặp lại sau rule tuning. | 20-40% |
Reopen rate | Tỷ lệ ticket bị mở lại sau đóng. | Không tăng |
Evidence coverage | Tỷ lệ AI recommendation có evidence reference. | 100% |
Cost per case | Chi phí model/tool/query trung bình cho một case. | Có baseline và trend giảm |
15. Rủi ro và biện pháp kiểm soát
Rủi ro | Tác động | Kiểm soát đề xuất |
AI học sai từ Tier 1 | Giảm accuracy, tăng false negative/false positive. | Chỉ dùng Tier 3 final verdict làm ground truth; Tier 1 là tín hiệu phụ. |
Fine-tune quá sớm | Model học nhiễu từ dữ liệu SOC chưa sạch. | Bắt đầu bằng RAG/case memory/calibration; chỉ fine-tune khi có dataset chuẩn. |
Không version prompt/model/rule | Không debug được vì sao AI sai. | Version mọi artifact và lưu prediction trace. |
Không có evidence reference | Tăng hallucination, analyst mất niềm tin. | Mọi verdict phải kèm evidence_used và query/reference. |
Action tự động quá mạnh | Có thể gây downtime hoặc block nhầm. | Action risk taxonomy, approval gate và rollback. |
Data nhạy cảm vào model | Rủi ro compliance và leakage. | Redaction, tenant isolation, policy gateway, opt-out training nếu dùng vendor. |
Không đo được hiệu quả | Không chứng minh ROI. | KPI baseline, eval dataset, monthly quality review. |
16. Khuyến nghị triển khai
Khuyến nghị chính Chọn kiến trúc hybrid: tận dụng AI native của vendor đang dùng, nhưng xây Common Ticket Hub + Learning Layer nội bộ để chuẩn hóa dữ liệu học, kiểm soát ground truth và giảm vendor lock-in. |
- Không triển khai auto-response toàn phần ở giai đoạn đầu; bắt đầu với triage, summarization, similar case retrieval và detection tuning draft.
- Đặt Tier 3 final verdict làm ground truth, bắt buộc có evidence và approved_for_learning.
- Dùng case memory/RAG để học an toàn trước; fine-tuning chỉ là giai đoạn sau.
- Thiết kế mọi recommendation của AI theo mẫu: verdict, confidence, evidence, similar cases, missing checks, recommended next steps, approval requirement.
- Duy trì hard-case dataset để kiểm thử hồi quy trước mọi thay đổi prompt/model/rule.
- Kết nối SOAR theo nguyên tắc least privilege và phân loại action theo risk.
Recommended target state:SIEM / XDR / EDR / IAM / Cloud / Email / Firewall -> Normalization & Evidence Layer -> Common Ticket / Case Hub -> Tier 1 Analysis + Tier 3 Final Verdict -> SOC AI Agent Orchestrator -> Case Memory + RAG + Feedback Learning -> Better Triage + Better Investigation + Better Detection17. Phụ lục: nguồn tham khảo
Nguồn tham khảo ưu tiên tài liệu chính thức của vendor và một số nghiên cứu mới về agentic SOC. Các URL được ghi để đội dự án kiểm tra chi tiết khi chọn giải pháp hoặc thiết kế tích hợp.
1. Microsoft Security Copilot documentation: https://learn.microsoft.com/en-us/copilot/security/
2. Microsoft Security Copilot product page: https://www.microsoft.com/en-us/security/business/ai-machine-learning/microsoft-security-copilot
3. Google Cloud - Agentic AI for Security Operations: https://cloud.google.com/security/resources/agentic-soc
4. Google Security Operations product page: https://cloud.google.com/security/products/security-operations
5. CrowdStrike Charlotte Agentic SOAR: https://www.crowdstrike.com/en-us/platform/charlotte-ai/agentic-soar/
6. Palo Alto Networks - The SOC Is Now Agentic: https://www.paloaltonetworks.com/blog/2026/02/soc-agentic-next-evolution-cortex/
7. Splunk AI Assistant in Security: https://www.splunk.com/en\_us/products/splunk-ai-assistant-in-security.html
8. Responsible AI for Splunk AI Assistant in Security: https://www.splunk.com/en\_us/about-splunk/splunk-data-security-and-privacy/responsible-ai-for-splunk-security-ai-assistant-agentic-capabilities.html
9. Splunk Enterprise Security editions: https://help.splunk.com/en/splunk-enterprise-security-8/enterprise-security-editions
10. SentinelOne Purple AI: https://www.sentinelone.com/platform/purple/
11. SentinelOne Purple AI Athena release: https://www.sentinelone.com/press/sentinelone-brings-deep-security-reasoning-agentic-detection-and-response-and-hyperautomation-workflows-to-any-siem-or-data-source-with-purple-ai-athena-release/
12. AgentSOC: A Multi-Layer Agentic AI Framework for Security Operations Automation: https://arxiv.org/abs/2604.20134
13. GenAI-Driven Threat Detection with Microsoft Security Copilot: https://arxiv.org/abs/2605.20896
14. Cyber Defense Benchmark: Agentic Threat Hunting Evaluation for LLMs in SecOps: https://arxiv.org/abs/2604.19533